| |
| EE Times: Design
News Using SystemVerilog for functional verification | |
| Tom Fitzpatrick (12/05/2005 9:00 AM EST) URL: http://www.eetimes.com/showArticle.jhtml?articleID=174900365 | |
| The need to
improve functional verification productivity and quality continues to
grow. The 2004/2002 IC/ASIC Functional Verification Study, by Collett
International Research, shows that logic or functional errors are the
leading cause of ASIC respins (Figure 1).
With 75 percent of respins caused by these errors, the need for a higher quality approach to verification has been clearly identified. Design and verification engineers face the question of how to move from their existing functional verification processes toward a more advanced functional verification methodology that includes automated testbench techniques such as assertions, constrained-random data generation, and functional coverage.
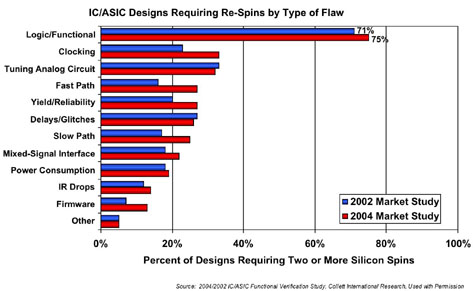 Figure 1 The problem of functional errors is getting worse, calling for new verification techniques and technologies.
The ability to add these advanced functional verification constructs to the SystemVerilog language, so they can be used seamlessly with existing HDL-based environments, was one of the main motivations behind its standardization by the Accellera standards organization. The effect is similar to that which occurred when the standardization of VHDL and Verilog created a design and verification environment that was far more productive than the previous paradigm. Effective verification requires two critical elements, both of which are promoted by SystemVerilog. First, the verification environment must be set up to detect bugs as automatically as possible, which is where features like assertions, automated response checkers, and scoreboards come in handy. Second, it must be able to generate the proper stimulus to cause bugs to happen. Stimuli may be generated via either directed tests or constrained random techniques that exercise a wide range of scenarios with a relatively small amount of code. Of course, once randomization is incorporated in the testbench, functional coverage is required to determine which of the possible scenarios actually occurred. While it is true that to take full advantage of an automated testbench environment, it is best to start from scratch and architect your environment appropriately, it is often the case that projects teams, particularly those at a critical stage that feel the need to quickly improve their process, do not have the luxury of building an elaborate test environment from the ground up. In these situations, the ability to adopt advanced techniques incrementally can be the difference between successful completion of the functional verification task and the need to respin the chip. You dont have to adopt assertions, constrained-random data generation, and functional coverage at the same time to be productive. Theyre more useful when used together, but they are effective when used separately as well. Behavioral and functional coverage assertions Assertions are by far the easiest of these techniques to adopt incrementally, so they are a good place to start. Because assertions are orthogonal to the design, they can be thought of as a separate layer of verification added on top of the design itself. Designers should write assertions that describe the behaviors they expect the environment to exhibit, the behaviors they want to model, and specific structural details about the design implementation. Designers should also write functional coverage assertions to identify corner cases that the verification environment must properly stimulate. Verification teams typically write assertions that deal more with the end-to-end behavior of a block or system, specifying the behavior independently of the specific implementation choices of the designer. Once you decide the type of behavior or corner case you want to specify with assertions, the next question is whether to write the assertion explicitly in a language, such as SystemVerilog, or whether to use an assertion library, such as the Accellera Open Verification Library (OVL) or the Mentor Graphics 0-In CheckerWare library. Libraries have certain advantages, particularly for new users, in that they are easy to instantiate in the design, requiring little effort on the designers part to specify the desired behaviors. However, those behaviors must be contained in the library. Libraries are also high quality, since they are created by experts and have been proven over time by many teams on many projects. Libraries have the additional benefit of including specific functional coverage metrics related to the behavior being checked. However, if the specific behavior is not directly included in an assertion library, then it is necessary to write the assertion explicitly in SystemVerilog or some other assertion language. The semantics of assertions in SystemVerilog ensure that only stable values of signals are examined, so race conditions are eliminated, especially in multi-clock circuits. In addition, assertions written in SystemVerilog can themselves be parameterized, so it is often the case that a small group of assertion experts can write a custom assertion library for use on a specific project. Using the assert statement, SystemVerilog properties and sequences carry the obligation of proof and, thus, act as monitors in simulation that automatically check the behavior of the design. If an assert statement fails, it is, by definition, a problem. The locality of the assertion to the problem, both logically and temporally, makes it faster and easier to debug. For example:
In this example, the property prop1 is declared with formal arguments, a and b, and describes the behavior: when a occurs, it is implied that b will occur on the next clock. When the property is instantiated, it is passed signals c and d, which replace formal arguments a and b, respectively. When using the cover statement to implement functional coverage assertions, the role is more one of detection as opposed to checking. Thus, if a cover sequence fails, it is not an error per se; it simply means that the specified behavior has not been adequately exercised by the testbench. Thus specified, the cover directive allows properties and sequences to serve as control-oriented functional coverage points for detecting whether specific temporal behaviors have or have not been exercised. The other type of functional coverage assertions, data-oriented functional coverage, sample data values at specific points throughout the simulation and is accomplished via the SystemVerilog covergroup construct. As with assertions, covergroups can be added as an incremental layer on top of existing tests. Suppose we have a bus-based system in which the protocol supported four different transaction types to four different address ranges. We could write a covergroup to track the data as follows:
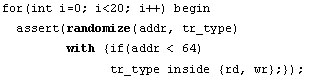
With this covergroup, whenever the smp event occurs, the values of addr and tr_type will be sampled. The bins serve as counters, so we know how many times the address value was in each of the four equal-size ranges from 0255 and how many of each transaction type occurred. Notice that this can be added to any existing Verilog design. There are two tricks to make a covergroup most effective. The first is to build into the covergroup the ability to correlate the sampled data into information to determine if your testbench has in fact exercised the desired scenarios. With four address ranges and four protocol modes, perhaps we want to determine that we have successfully generated each of the 16 possible combinations. By including the cross statement, the covergroup is set up to directly answer whether we have indeed exercised all possible combinations on the bus, with a simple call of the get_coverage() method of the covergroup (cov1.addr_type.get_coverage()). We can now easily place our test in a loop that continues until all combinations are hit. The other trick is to sample the values only at the appropriate times. This can be done in a number of ways, but rarely if ever will you sample a covergroup on every posedge clk. The sampling of the covergroup is defined by the sample event in the definition. This event can be triggered by an FSM or other mechanism in the design or by a bus monitor that indicates that a valid transaction has occurred on the bus. Also, since assertion sequences are themselves events in SystemVerilog, the covergroup can be sampled on successful completion of a sequence. The built-in sample method of the covergroup is another way to sample the values only at the appropriate times. When the bus monitor detects a valid transaction, it could simply call the cov1.sample method to cause the data to be sampled explicitly. Note that SystemVerilog allows methods to be called from within a sequence, so the sampling could be controlled from within a sequence as well. Randomized and constrained stimulus Although they can be used independently, both control-oriented and data oriented functional coverage are more useful when coupled with constrained-random stimulus generation. The use of randomization and constraints offers many substantial improvements in verification productivity. Other languages provide these features only through the use of complex object-oriented or aspect-oriented programming techniques. While SystemVerilog includes randomization and constraints within its object-oriented framework, it also provides several ways of deploying these features without having to learn object-oriented programming, thus enabling broader use of these advanced methodologies. The first step in adopting randomization in SystemVerilog is to employ the randsequence block (Figure 2). This block allows you to specify individual statements (which can also be tasks) that get executed in random order, depending on weighted probabilities and other powerful looping constructs. The randsequence block can be used to generate stimulus within a particular test, if each statement in the block generates, for example, a different type of bus cycle or packet type. Since each walk through the block causes the statements to execute in a different order, the order of the discreet stimuli will be random and therefore more likely to expose corner cases. Among other things, constraints allow the randsequence block to be used to generate random instruction streams, where the constraints ensure that complex code structures, such as loops, are generated correctly. This would be almost impossible in a completely random environment.
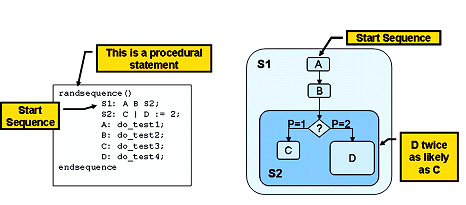 Figure 2 The purpose of a randsequence is to interleave the scenarios of various tests to inject a more complex and realistic set of scenarios into the DUT.
Taking things to a slightly higher level, each statement in the randsequence block can be a task that encapsulates a complete test (which can itself be directed or random). The key here is to realize that not all operations of the chip execute directly out of reset, so the end of one test can leave "crumbs" behind that may break other tests. This technique is not new; I employed it many years ago by using Perl to call Verilog tests in a random order. The novelty is that this capability is now part of the language. The other powerful randomization feature of SystemVerilog is the randomize with function. This function started out as a built-in method of any class with a random element in it, but the Accellera committee quickly realized the power of being able to apply constraints to the randomization of regular variables as well. The with block allows constraints to be specified for the randomization, using the exact same syntax as constraints for object-oriented randomization. This allows you to specify more complex constraint relationships, and makes those relationships easier to read. Since the randomize function is just a function in SystemVerilog, it can be used anywhere the usual Verilog random functions such as $random and $urandom can be used. Consider:
Notice how much clearer the randomize with statement is, both in terms of specifying the relationship between addr and data and in terms of its intelligibility. This makes it much easier to debug as well. Transaction-level stimulus When one considers the stimulus generation task from a slightly higher level of abstraction, it is useful to consider stimuli as a sequence of transactions that the testbench generates. A testbench written in terms of transactions allows you to think about the stimuli in terms of what should be happening, without getting bogged down in the details of how it happens. The how can be checked by your bus monitor using assertions, for example, but you really want to keep your test, which is driving the stimuli, at the transaction level. The presence of randomize with in SystemVerilog allows for the randomization of transaction-level stimuli, including the specification of constraints. Consider our earlier example of a bus-based system with four address ranges and four protocol modes. Suppose that the peripheral in the lowest address range only supports single word transactions. We could still randomly generate transactions using the randomize function:
Notice how we randomize both the address and the transaction type, with the constraint further limiting the allowable transaction types based on the value of the address. As more complex transaction types are created, the same mechanism can be used. It is true that the object-oriented features of SystemVerilog make it easier to create reusable test environments by allowing constraints and other aspects to be controlled or overridden via inheritance. However, for those not ready or not willing to pursue object-oriented programming, the ability to write tests and constraints at the transaction level greatly enhances the effectiveness of tests. What is required to facilitate reuse in this type of environment is the proper use of partitioning in the testbench. Once the test generates the proper transaction-level stimulus, it is necessary for the testbench to include a driver component to take that transaction and turn it into pin-wiggles to the device-under-test (DUT). If we set up our environment such that the test passes the transaction via a standard interface to drive the DUT pins, it allows the driver interface to be modified independently of the test itself (Figure 3). The driver becomes a protocol-specific module (or interface, in SystemVerilog) with a standard API through which the testbench communicates in terms of transactions. This allows us to modify the driver, either to tweak the protocol or even replace it with a completely different protocol, as long as the transaction-level API for the testbench remains consistent.
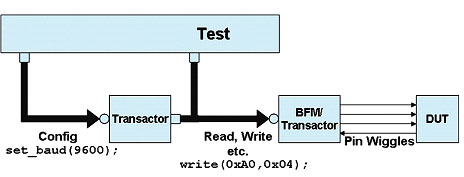 Figure 3 By isolating the test from low-level implementation changes and allowing randomization of higher-level operations, transaction-based verification keeps the test focused on what should happen.
Despite all the literature lauding object-oriented programming as the be-all-end-all of verification coding, you can significantly improve your existing methodology by employing a few of SystemVerilogs powerful features without having to spend the time and effort to become an object-oriented programming expert. SystemVerilog promotes advanced functional verification constructs that automate the detection of bugs and the thorough coverage of your designs, including hard-to-reach corner cases. A colleague of mine used to repeat the bromide that the best is the enemy of the good. One can always do more, of course, but the quality and productivity of your testbench environment will be better if you go ahead and adopt these features incrementally rather than not at all. Tom Fitzpatrick (tom_fitzpatrick@mentor.com) is a verification technologist with Mentor Graphics Design Verification & Test Division.
| |
| All material on this site Copyright © 2006 CMP
Media LLC. All rights reserved. Privacy Statement | Your California Privacy Rights | Terms of Service | |